일반적으로 머신러닝에서는 지도학습(supervised learning)과 비지도학습(unsupervised learning)이 있습니다. 저는 오늘 스터디에서 지도학습에 대한것을 알아보려고 합니다. 😊
지도학습이란?
내가 알고있는 지도학습이란 우선 정답이 있는 데이터를 활용해 데이터를 학습시키는 것이라고 알고있다.
한줄로 설명하자면 입력값이 X가 주어지면 입력값에 대한 Label(Y)을 주어서 학습시키는게 지도학습이다.
- 비지도 학습보다는 더 단순하고 일반적이다.
- 레이블이 지정된 데이터 즉, 분류된 데이터를 사용한다.
- 시간과 메모리가 많이 소요될 수 있다.
- 데이터셋을 사용자가 만들다보니까 오류가 발생할 수 있다.
- 신뢰할 수 있는 데이터셋을 사용해야한다.
- 지도 학습은 주어진 레이블로만 학습이 된다.
지도 학습의 알고리즘 종류
지도 학습의 알고리즘은 크게 두가지가 있다.
1️⃣ 분류(Classification)
입력 변수를 통해 범주(클래스, 그룹)을 예측하는 것
패턴 인식이 뛰어나 이미지 인식과 같은 용도에서 많이 쓰인다. 예를 들어 동물 데이터셋이 주어졌을때 각 이미지가 개인지 고양이인지 등을 판단할 때 많이 쓰인다.
분류 안에서도 이중분류(Binary Classification)와, 다중 클래스 분류(Multi-Class Classification) 두가지가 있다.
이중분류는 말 그대로 범주가 두 개인 경우이고 다중 클래스 분류는 범주가 두 개 이상인 경우를 말한다.
로지스틱 회귀
일반적인 선형 회귀는 연속적인 값을 예측하는 데 사용되지만, 로지스틱 회귀는 분류하는데에 사용하는 모델이다. 특히 이진 분류 문제(binary classification)를 해결하는데에 적합하다.
로지스틱 회귀 모델은 일종의 확률 모델로 선형 관계성을 기반으로 하는 모델이며 0과 1사이의 값으로 나오고 어떤 임계점을 기준으로 분류하는 기법이다.
스터디 하는 사람들이랑 이야기해본 결과 로지스틱 회귀는 SVM(Support Vector Machine)을 개선하기 위해나온게 아닐까 하는 생각이 든다.
장점
- 분류 모델이지만 확률을 구할 수 있다.
- 속도가 빠르다.
단점
- 복잡한 패턴을 학습할 시 선형모델이므로 과소적합이 발생할 수 있다.
- 정확성을 보장할 수 없다.
여기서 결과를 0과 1사이의 확률값으로 변환할때에 시그모이드 함수가 사용된다.

SVM(Support Vector Machine)
SVM은 두 클래스로부터 최대한 멀리 떨어져 있는 결정 경계를 찾는 분류기
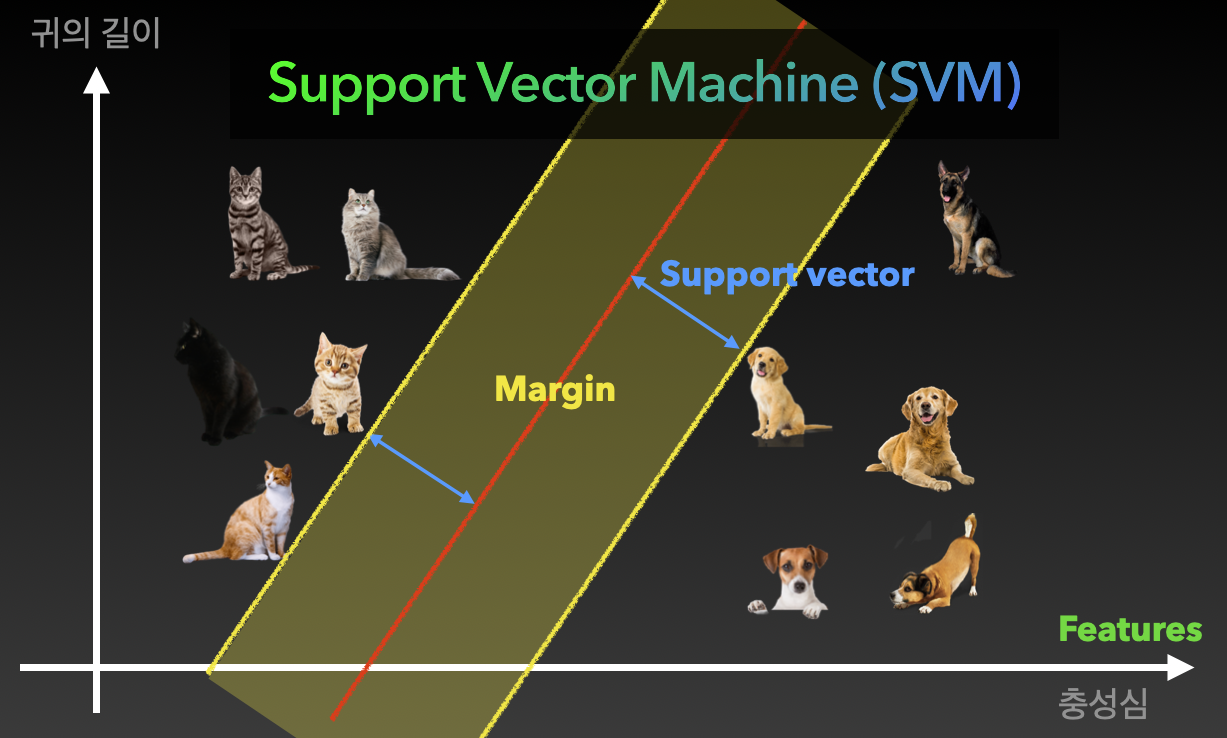
장점
- 데이터를 잘 분류할 수 있다.
- 이상치에 영향을 덜 받는다.
- 새로운 데이터 대해서도 잘 작동한다.
단점
- 학습 속도가 느리다.
- 메모리 사용량이 크다.
- 데이터가 선형으로 나눠지지 않을 때 모델을 만들기 어렵다.
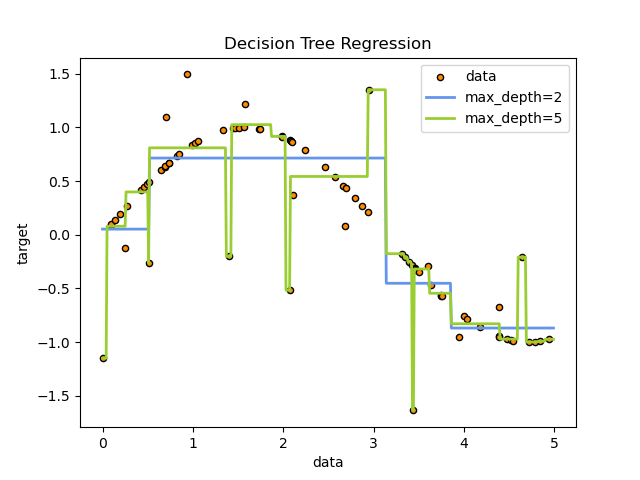
의사 결정 나무(Decision Tree)
데이터를 분석하고 패턴을 파악하여 결정규칙을 나무 구조로 나타낸 기계학습 알고리즘이다. 오버피팅에 취약하기 때문에 앙상블 기법이나, 랜덤포레스트랑 같이 사용하는 경우가 많다.
의사 결정 나무는 불균형한 데이터가 결과에 치명적이다.
장점
- 해석하기가 편하다.
- 데이터 사전 작업이 많이 필요 없다.
단점
- 오버피팅이 잘 일어날 수 있다.
아래 그래프를 보면 깊이가 깊어질수록 data를 잘 따라가는게 보인다. 좋게 보면은 데이터를 잘 잡을 수 있다고 볼 수 있겠지만 오버피팅 관점으로 본다면 세세한것까지 다 잡혀 오버피팅이 일어날 수 있다.
'스터디' 카테고리의 다른 글
| [스터디] 자바 신입 개발자 면접준비 (1) | 2024.05.05 |
|---|---|
| [스터디] 3일차 머신러닝-지도학습(회귀), 평가지표 (0) | 2024.03.27 |
| [스터디] 2일차 머신러닝-지도학습 (0) | 2024.03.22 |